
前言:
到目前為止,我們已經知道了四種和 BigQuery 溝通的方法,也知道如何查詢的公共數據集。
但是在我們大部分的使用情境,還是會需要上傳自己的資料。那麼,BigQuery 又吃哪些類型的資料呢? 我們繼續看下去吧!
我們在前面介紹 BigQuery 的時候,就有提到 BQ的好處是彈性大,沒錯,他支援非常多種的資料類型,下圖我們列出幾個常用的資料類型:
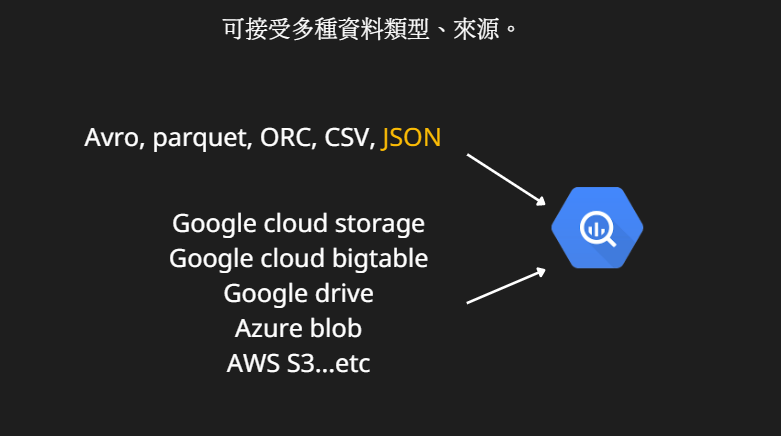
資料類型:
Avro、Parquet和 ORC,這三個都是大數據文件的格式,並且是基於Hadoop文件系統優化出的存儲結構,關於這類型的數據請參考這裡。
CSV相信大家都很熟,這裡就不再贅述。
JSON 也是很常使用的一種資料格式,JSON的全名是 JavaScript Object Notation ,主要是以 key value 的形式儲存,大概會長下面這個樣子:

資料來源:
Google cloud storage:
在 GCP 上的服務,是 Object Storage 的形式,使用上存在配額限制,比如單個檔案不能大於 5TB。
Google cloud bigtable:
在 GCP 上的服務,是 NoSQL Wide column的形式。
Google drive:
這個我們平常也很常使用,不再贅述。
Azure blob:
在 Azure 上的服務,是 Object Storage 的形式,
AWS S3:
在 AWS 上的服務,是 Object Storage 的形式。
其他注意事項:
關於 BigQuery 的 datatypes,請參考這裡。
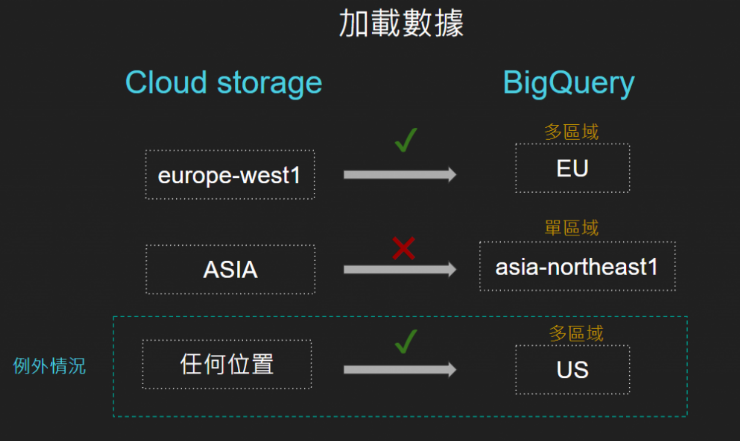
關於資料的存放位置:
BigQuery 的資料是存在不同的國家和城市,使用上需注意儲存區域和地區,以確保相關的服務可以互相串接。

Summary:
(1) BigQuery 支援的資料類型有非常多種格式,包含 Avro, parquet, ORC, JSON和 CSV。
(2) BigQuery 支援的資料來源有很多種,包含 Google cloud storage, Google cloud bigtable, Google drive, Azure blob, AWS S3。
Reference:
https://cloud.google.com/bigquery/docs/loading-data-cloud-storage-csv

